







Probably the most commonly used SQL keywords, Select and From are the minimum commands you would need to see data from a table.
Select Statement is used to tell the database what data you would like to see
The Select Statement is made up of the following parts:


If you are not in my class, but want to follow along, here is a data file you can import into SQL Server:
Instructions for importing the Excel File to SQL Server : Instructions






Document databases, also known as document-oriented databases or NoSQL databases, are a type of non-relational database that store data in a semi-structured format as documents. Unlike traditional relational databases which store data in tables, with rows and columns, document databases store data in flexible, nested structures that can more closely match the data’s natural hierarchical relationships.
Some of the most popular document databases include MongoDB, Couchbase, and RavenDB. These databases are often used in web and mobile applications that need to store large amounts of semi-structured or unstructured data, such as user profiles, product catalogs, and social media feeds.

Advantages of Document Databases
Disadvantages of Document Databases
In conclusion, document databases are a type of NoSQL database that are well-suited for storing large amounts of semi-structured or unstructured data. They offer advantages such as flexibility, performance, scalability, and ease of use, but also come with disadvantages such as a lack of consistency, lack of transactions, and increased complexity as the data grows. When choosing a document database, it’s important to consider your specific use case and requirements, and weigh the advantages and disadvantages carefully.

Here is a table of the most commonly used data types in SQL Server
| Data Type | Description |
| Char() | Fixed length string, unused spaces get padded and eat up memory: size 0-255 |
| Varchar() | Variable length string, unused spaces don’t use memory: 8000 chars |
| Nvarchar() | Designed to handle Uni Code data (UFT-8): 4000 chars |
| nvarchar(max) | 536-870-912 characters |
| Text | Up to 2GB of text data |
| Identity(x,y) | Auto incrementing number with x being starting point and y = steps, so Identity(1,1) starts and1 and counts by 1 |
| INT | integer (whole number, no decimals) |
| Decimal(x,d) | floating point decimal number, x is size, d is number of places after the decimal |
| float(n) | floating precision number, Float(24) = 4-bytes, Float(53) = 8-bytes — float(53) is default |
| Bool or Boolean | Binary choice, 0 = False and 1 = True |
| Date | Date data type “YYYY-MM-DD” (if set to US settings) |
| DATETIME | datetime data type “YYYY-MM-DD HH:MM:SS” (if set to US settings) |
| TIME | Time “HH:MM:SS” |
| YEAR | year in for digit representation (ex 1908,1965,2011) |
We will be using SQL Server Management Studio in the following lessons. If you have SQL Server installed on your machine, search for MS SQL Server Management Studio in programs or search for SSMS. If you need to install MS Sql Server: click here
Once it opens, enter the server you are looking to connect to and pick your authentication method (I’m using Windows Authentication, but you could set up a SA account and use Server Authentication)

If you properly connect to the server, you should get an object explore like the one seen below

If you are working on work or school SQL Server, you may not have rights to create a database, you will most likely have a database assigned to you that you can build tables in. You can skip to the table creation part of the lesson.
Right click on database in the object explore, click New Database

Next name your new database, leave all other settings as is. Click Ok

Your new database’s name will appear in the list of databases now

This is my preferred method. And again, we will just be using the default settings here to make this lesson easier.
Click the New Query Button to open a new query window

In the new window, type the following (note the semicolon at the end of the line, this is standard SQL and used by most system. SQL Server allows you to replace ; with the word GO. It is completely legit, I just don’t use it because no other system does either)
Create Database Test2;Then click Execute


If you don’t see your new database appear in the Object Explorer, right click Database ,and select Refresh

From your query workspace, select your database from the drop down menu

Go to a query workspace and type in the following code
use Test;I tend to like this method because you can put it on the top of code you might share and it will guide people to the right database
Hit the + next to your database to expand

Right Click Tables > New > Table…

Now manually enter column names and datatypes for your new table

Once you are done. Click the X to close this tab. You will be first asked to save changes (yes) then you will be asked to Name you new table
From your query window, use the following code to create a table:
Create Table tableName (
Column 1 datatype,
Column 2 datatype));The syntax is pretty straightforward. The code below with create a table names Contractor with 6 columns
create table Contractor (
ContractorID int primary key,
CompanyNM nvarchar(255),
LastNM nvarchar(255),
FirstNM nvarchar(255),
Phone nvarchar(50),
email nvarchar(255));Note I am able to assign the primary key to the first column by putting primary key after the datatype
Copy this into your SQL Server — Note you can run segments of code by highlighting them first and then hitting execute. Only the highlighted code is run.

To see if it runs successfully, expand your tables segment out on your object explorer

Let’s add another table. Copy the following code over to SQL Server and execute just like before
create table Permit (
PermitID nvarchar(255) primary key,
StartDate date,
ProjectTitle nvarchar(255),
[Location] nvarchar(255),
Fee money,
ContractorID int);Now lets connect the two tables with a foreign key/primary key relationship. To create this relationship, use the following code
alter table Permit
add foreign key(ContractorID) References Contractor(ContractorID);Note I am working with the table Permit, I am saying the Column ContractorID is the foreign key in the Permit table related to (References) the ContractorID column in the Contractor table
Use the following code to add data to the two tables
insert into Contractor
values (1, 'Front Poarch Construction', 'Poarch','Ken', '555-1234', 'poarch@fpc.com'),
(2, 'Mikrot Construction', 'Mikrot', 'Kim', '555-5678', 'MK@mikrot.com'),
(3, 'Sobaba Construction','Sobata', 'Jeri', '555-9012', 'SJ@sobaba.com');
Insert into Permit
values ('B12345','2022-01-01','My Deck','Branchburg',550.00,3);The syntax is basically
Insert into <tableName>
Values (data separated by commas, rows wrapped in parathesis, again separated by columns)
You can download the following file if you want to play along
Right click on your database, Tasks> Import Data

Click Next on the first Window to pop up

Choose Microsoft Excel as Data source, browse for your file, make sure First row has column names is selected, click Next

Select SQL Server Native client as destination. If you have more than one to pick from, choose the higher number. Click Next

Leave default options – Click Next

Select the top option, You can change the destination table name if you choose.

I choose to change it and then click Next

Leave default selections, click Next

Click Finish

Make sure you got 75 rows Transferred and click close

Permit_Landing is a Landing Table. That means a table you load data into initially before it is verified and moved to production tables
Refresh your database to see the new added tables. Right click on Permits_Landing and Select Top 1000 Rows

A query window should pop up and give you the following results

The goal is to move this data to the Permit table. But note, the Permit Table has a column ContractorID that is not present in Permits_Landing. So we have to use code like seen below.
insert into permit (PermitID, StartDate, ProjectTitle, [Location], Fee)
select * from Permit_Landing;Note, we have Insert Into Permit (like before) — but we now include a list columns. We only list the columns we want to load data into. Since we don’t have ContractorID column in the landing table, we will not include it here.
Also, notice the [] around Location. This is because location is a SQL key word. To let SQL Server know we are talking about a column and not a keyword, we put square brackets around it
Finally, we choose the data to load into the table using a simple select statement: Select * from Permit_Landing
I made these video walkthroughs as an alternative to following the lab in the text book. I know some people (myself included) learn better from watching videos.
This is a walkthrough for Lab 1 for my course on Database Development and Design. Feel free to watch video, but I will not be sharing any files as they were not created by me and I do not have permission to share them.
•How do we handle the situation when we have multiple classes but realize the classes have a significant amount of information in common?
•How do we handle the situation when we have a single class but realize that there are differences among the different objects in that class that may drive us to break up the class into two classes?
When the majority of the information about two types of objects are the same, but there exists some different specialized data

•Let’s say this class already exists for a small startup company
•All employees have an ID, firstName, lastName, and salary
•The startup has grown enough that they now want to hire consultants
•Instead of salary, consultants have an hourly rate

•Subclasses (or inherited classes) contain the specialized information
•Permanent and Consultant are both subclasses of Employee
•Superclasses (top classes) should be as general as possible
•Future changes to the superclass would affect all subclasses
•Easy to add additional subclasses
When you have 2 or more existing classes and realize they have some information in common

Adding a superclass and pulling out the common information from the 2 subclasses into the superclass (the same as specialization only in the opposite direction)

•Generalization and Specialization are examples of inheritance

•SubClassA and SubClassB are both specialized types of SuperClass
•SubClassA and SubCLassB will have all the attributes of SuperClass in addition to their own attributes
An important first step for developing a data model is taking the time to learn about the data and how the data relates.
Remember not all data is useful. While you may wish to include data that does not directly relate to the problem, this can quickly become problematic as your data model can grow into an unmanageable mess.
Keep in mind, a data model should work for:
Lets start with an example of a soccer (football for all my non-US friends) club data model. Here is an example of a class you could build for holding team data:

The attributes are used to capture data about each team.
But let’s look at a new problem we haven’t really discussed yet:

Look at the AgeGroup above. If I asked you what teams are in the U-12 age group, as a human you could look at the table above and tell me that Rage and Hurricanes are. However, if you tried running a query for U-12, it would only return Rage, as U – 12 and U-12 are viewed as completely different terms by a computer.
To prevent this, one approach could be to create a new class


Now, U-12 will only appear once in the Agegroup table, this removes the risk of someone typing it in differently like in the table before. Integrity of data accuracy is something to consider when deciding how many tables to create.
Now lets look at the issue of team captains, considering a team captain is also a player. The diagram below shows there are 2 relationships between Player and Team classes. This is perfectly okay.

•Do you want to select objects based on the value of an attribute? Then you may want to introduce a class for that information.
(Ex: you want to see all teams that are in age group “U-12”)
•Do you need to store other data about this information? Then you may want to introduce a class for that information. (Ex: We are storing the team captain’s name but also want his/her email and phone number)
•Are you already storing similar information? Then you may want to use a relationship among existing classes. (Ex: the information about team captain is the same as the information about the players, so use that class with a new relationship)
Now consider the example of a building housing multiple companies. While the diagram below is not completely incorrect, I will argue against the relationship between Employee and Room. In this example, it appears that you can infer the Employee location through the Company-Room relationship. While having multiple route for data isn’t wrong, make sure they convey different information.


•Each employee belongs to one division
•Divisions are made up of many Groups
•The problem here is if you try to infer something that was not intended
•You know it’s a fan trap when you have 2 relationships with many cardinality on the outside ends

They way the data model is written, a division can have many different employees and a division can also belong to many different groups. So trying to determine what group an employee belongs to via their division is impossible in this data model.

•Each employee can belong to at most 1 group
•Each group belongs to 1 and only 1 division
•Divisions are made up of many Groups
•Can you answer the question, “What division does each employee belong to?”
•You know it’s a chasm trap when the connection is not always there or there is a gap in a route between classes

•Ann doesn’t belong to a group since the optionality is 0
•We can only determine division based on group assigned
•So we have no idea what division Ann is in
•Whenever there is a closed loop, check to see if the same information is being stored more than once (don’t be redundant).
•Make sure you are not inferring more than you should from a route. Always look out for the case when a class is related to two other classes with a cardinality of many at both outer ends.
•Ensure that a path is available for all objects. Are there optional relationships along the route?
You an even have a Self Relationship

•Say that a club requires an existing member to sponsor any new members
•You wouldn’t have a class for member and a class for sponsor because they have the same data
•You can represent this type of situation with a self relationship because objects of a class can be related to each other
This tutorial was created as supplemental material for my undergrad course in database design. You can find the full course here: Course
For this example, I want to create a new table. I have attached an Excel file below that you can download.
From access: External Data> New Data Source > From File > Excel

Check First Row Contains Column Headings and click Next

You can change the data types of the column, but I am just leaving them as is.. click next

Let Access add primary key > click next

Name your table and hit finish

Now if you click on the Employee table in the table list on the left you will see the results

Comparison operators are the symbols that let us check if something is equal to, greater than, less than, etc

Lets create a query using comparison operators
Click on Create > Query Design

Drag the Employee table into the query workspace

Add all the fields below and in the Criteria spot for Age, put >40

Right click the Query Tab and click Datasheet View

You can now see the results with employees only over the age of 40

Also remember, you can right click on Query1 tab and select SQL View to see the SQL code that runs the query

You can also use Between to select Criteria- Below will return everyone aged between 30 and 45

Now lets try querying dates
When working with dates, you need to put #’s before and after the date. If your Access is set to USA settings, we go MM/DD/YYYY, European (and most of the rest of the world) goes DD/MM/YYYY
The below query will return employees hired after Jan 1 2010

And here are the results

The entire purpose of related tables is that they allow you to query information from multiple tables at once. In this example we will be creating a query that looks at the Class and Teacher tables we built in the intro to MS Access Lesson: link to lesson

To start, we will select Create from the Menu bar and Query Design from the Ribbon

Next drag the Teacher and Class table over to the blank space for Query1

down below you can select the columns (fields) you want to bring in from the tables.

Next, put all the all the available columns in the Fields below


Right click on the query tab and select datasheet view.
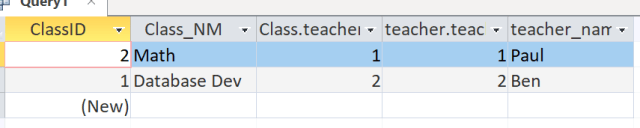
Note the two tables are matched up by the teacherID in two different tables. That is the relationship. That is how relational database allow tables to interact

Lets remove the teacherID from the query
Go back to design view and uncheck the columns to hide them from the query

To see the results, click on the Query1 tab and select Datasheet view


So you can see, our query returned information found in 2 different tables
Now, let’s right click on Query1 tab and select SQL View

This is how you would write this query using SQL

Select Class.ClassID, Class.Class_NM, teacher.teacher_name — This means that we want to see these three columns. Note the table name is in front, followed by the column or field name, separated by a ‘.’ This is common practice in SQL. It tells the database which table the field is in. And in situations like the teacherID column that is found in both tables, it clarifies which one you want.
from teacher INNER JOIN Class ON teacher.teacherID= Class.TeacherID; — this is a typical join statement. It says use both teacher and Class tables, and match the records up using the TeacherID field.
For more information in Joins, check my SQL Intro to Joins and SQL 4 Types of Joins
Back to Main Course Page: Course