I made these video walkthroughs as an alternative to following the lab in the text book. I know some people (myself included) learn better from watching videos.
This is a walkthrough for Lab 1 for my course on Database Development and Design. Feel free to watch video, but I will not be sharing any files as they were not created by me and I do not have permission to share them.
•How do we handle the situation when we have multiple classes but realize the classes have a significant amount of information in common?
•How do we handle the situation when we have a single class but realize that there are differences among the different objects in that class that may drive us to break up the class into two classes?
Specialization
When the majority of the information about two types of objects are the same, but there exists some different specialized data
•Let’s say this class already exists for a small startup company
•All employees have an ID, firstName, lastName, and salary
•The startup has grown enough that they now want to hire consultants
•Instead of salary, consultants have an hourly rate
•Subclasses (or inherited classes) contain the specialized information
•Permanent and Consultant are both subclasses of Employee
•Superclasses (top classes) should be as general as possible
•Future changes to the superclass would affect all subclasses
•Easy to add additional subclasses
Generalization
When you have 2 or more existing classes and realize they have some information in common
Adding a superclass and pulling out the common information from the 2 subclasses into the superclass (the same as specialization only in the opposite direction)
Inheritance
•Generalization and Specialization are examples of inheritance
•SubClassA and SubClassB are both specialized types of SuperClass
•SubClassA and SubCLassB will have all the attributes of SuperClass in addition to their own attributes
An important first step for developing a data model is taking the time to learn about the data and how the data relates.
Remember not all data is useful. While you may wish to include data that does not directly relate to the problem, this can quickly become problematic as your data model can grow into an unmanageable mess.
Keep in mind, a data model should work for:
A set of assumptions
Function within the limitations of the problem scope
Lets start with an example of a soccer (football for all my non-US friends) club data model. Here is an example of a class you could build for holding team data:
The attributes are used to capture data about each team.
But let’s look at a new problem we haven’t really discussed yet:
Look at the AgeGroup above. If I asked you what teams are in the U-12 age group, as a human you could look at the table above and tell me that Rage and Hurricanes are. However, if you tried running a query for U-12, it would only return Rage, as U – 12 and U-12 are viewed as completely different terms by a computer.
To prevent this, one approach could be to create a new class
Now, U-12 will only appear once in the Agegroup table, this removes the risk of someone typing it in differently like in the table before. Integrity of data accuracy is something to consider when deciding how many tables to create.
Now lets look at the issue of team captains, considering a team captain is also a player. The diagram below shows there are 2 relationships between Player and Team classes. This is perfectly okay.
•Do you want to select objects based on the value of an attribute? Then you may want to introduce a class for that information.
(Ex: you want to see all teams that are in age group “U-12”)
•Do you need to store other data about this information? Then you may want to introduce a class for that information. (Ex: We are storing the team captain’s name but also want his/her email and phone number)
•Are you already storing similar information? Then you may want to use a relationship among existing classes. (Ex: the information about team captain is the same as the information about the players, so use that class with a new relationship)
Multiple Companies in One Building
Now consider the example of a building housing multiple companies. While the diagram below is not completely incorrect, I will argue against the relationship between Employee and Room. In this example, it appears that you can infer the Employee location through the Company-Room relationship. While having multiple route for data isn’t wrong, make sure they convey different information.
Fan Trap:
•Each employee belongs to one division
•Divisions are made up of many Groups
•The problem here is if you try to infer something that was not intended
•You know it’s a fan trap when you have 2 relationships with many cardinality on the outside ends
They way the data model is written, a division can have many different employees and a division can also belong to many different groups. So trying to determine what group an employee belongs to via their division is impossible in this data model.
Chasm Trap
•Each employee can belong to at most 1 group
•Each group belongs to 1 and only 1 division
•Divisions are made up of many Groups
•Can you answer the question, “What division does each employee belong to?”
•You know it’s a chasm trap when the connection is not always there or there is a gap in a route between classes
•Ann doesn’t belong to a group since the optionality is 0
•We can only determine division based on group assigned
•So we have no idea what division Ann is in
Multiple Routes Between Classes:
•Whenever there is a closed loop, check to see if the same information is being stored more than once (don’t be redundant).
•Make sure you are not inferring more than you should from a route. Always look out for the case when a class is related to two other classes with a cardinality of many at both outer ends.
•Ensure that a path is available for all objects. Are there optional relationships along the route?
You an even have a Self Relationship
•Say that a club requires an existing member to sponsor any new members
•You wouldn’t have a class for member and a class for sponsor because they have the same data
•You can represent this type of situation with a self relationship because objects of a class can be related to each other
From access: External Data> New Data Source > From File > Excel
Check First Row Contains Column Headings and click Next
You can change the data types of the column, but I am just leaving them as is.. click next
Let Access add primary key > click next
Name your table and hit finish
Now if you click on the Employee table in the table list on the left you will see the results
Comparison Operators
Comparison operators are the symbols that let us check if something is equal to, greater than, less than, etc
Lets create a query using comparison operators
Click on Create > Query Design
Drag the Employee table into the query workspace
Add all the fields below and in the Criteria spot for Age, put >40
Right click the Query Tab and click Datasheet View
You can now see the results with employees only over the age of 40
Play around with it, try less than 40, >= or <=, just try some different queries
Also remember, you can right click on Query1 tab and select SQL View to see the SQL code that runs the query
You can also use Between to select Criteria- Below will return everyone aged between 30 and 45
Dates
Now lets try querying dates
When working with dates, you need to put #’s before and after the date. If your Access is set to USA settings, we go MM/DD/YYYY, European (and most of the rest of the world) goes DD/MM/YYYY
The below query will return employees hired after Jan 1 2010
The entire purpose of related tables is that they allow you to query information from multiple tables at once. In this example we will be creating a query that looks at the Class and Teacher tables we built in the intro to MS Access Lesson: link to lesson
To start, we will select Create from the Menu bar and Query Design from the Ribbon
Next drag the Teacher and Class table over to the blank space for Query1
down below you can select the columns (fields) you want to bring in from the tables.
Next, put all the all the available columns in the Fields below
You’ll notice the Fields all have their table names in front of them in the drop down. This is common SQL notation for <table>.<field>
Right click on the query tab and select datasheet view.
Note the two tables are matched up by the teacherID in two different tables. That is the relationship. That is how relational database allow tables to interact
Lets remove the teacherID from the query
Go back to design view and uncheck the columns to hide them from the query
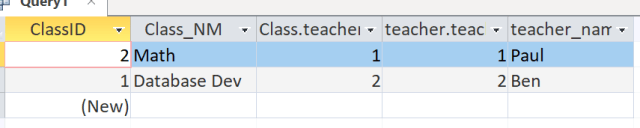
To see the results, click on the Query1 tab and select Datasheet view
So you can see, our query returned information found in 2 different tables
Now, let’s right click on Query1 tab and select SQL View
This is how you would write this query using SQL
Select Class.ClassID, Class.Class_NM, teacher.teacher_name — This means that we want to see these three columns. Note the table name is in front, followed by the column or field name, separated by a ‘.’ This is common practice in SQL. It tells the database which table the field is in. And in situations like the teacherID column that is found in both tables, it clarifies which one you want.
from teacher INNER JOIN Class ON teacher.teacherID= Class.TeacherID; — this is a typical join statement. It says use both teacher and Class tables, and match the records up using the TeacherID field.
MS Access is a all in one database solution provided as part of MS Office. Access was much more popular years ago when more powerful solutions such as Oracle an SQL Server couldn’t be effectively run on desktops. While Access’s time in the sun is definitely in decline, for someone new to concepts of databases, Access can be a great introduction.
Let’s start by creating a simple database. Open up Access and click on Blank Database
Give your blank database a name in the pop up window
By default, you’re new database will start with a Table1 with an ID column. Click the drop-down on the next column space to add a new column. For this example, let us select Short Text as our data type. Short text can handle any text up to 255 characters
After you set the datatype, you can click on the column name and rename it
Let’s add another column, set the datatype to number
Now click the X next to table1 and you will be prompted to name your table
Another way to build a table is through the table design feature
You can name your columns and select data types: Note AutoNumber is an auto incrementing datatype that works to provide you with an auto populating ID number
Access requires primary keys for all tables (something not required, but recommended in other systems like MySQL or SQL Server). To create a Primary Key, right click on ClassID and select Primary Key
Finally, let’s just use SQL to create a table. Select Create an then Query Design from the ribbon menu
Select SQL View
Put in the SQL below
create table teacher (
teacherID int primary key,
teacher_name varchar(255))
Click on the new teacher table in the left and you can fill in some data
Now let’s create a relationship between the Class and Teacher tables. Click on Database Tools > Relationships
Drag the Class and Teacher table into the blank sheet and click Edit Relationships
Click create new, select your tables and columns from the drop down, and select Enforce Referential Integrity and select the Create button
A Relationship line will appear, showing you your connection
When start on the design of a database there are few questions you need to ask right away:
Not to be dismissive, but do not simply build a database to the specs of a request
Take stock of the data at hand, ask around if there is related data that also might be included
Think about what users will be doing with the data
As best you can, try to anticipate other uses for the data that come up
Focus on the type of data you are dealing with, and how it can be best used/store
Don’t only focus on the current use of the data, consider the data may find other uses as well
Now, let’s look at database development through the lens of a software development cycle
Keep in mind, this process is not simply linear. This process, in the real world, goes through many iterations. Change management is good idea to put in place. It helps you to deal with issues like:
New data sources
New requirements from business users
Technology platform changes in your organization
To get started, we need to come up with a problem statement, something that can describe the problem we are trying to solve. Use cases are commonly used when developing problem statements. Use cases help to demonstrate how a user will be interacting with your database:
Transactional – think like a cash register, adding new transactions to database, updating inventor
Reporting base – data doesn’t change often, people want to look more at aggregate numbers over the details of each transaction. (End of the day reporting – what is the final sales total from the cash register)
You can use Unified Modeling Language (UML) to create your use case. UML uses a series of diagramming techniques to help visualize system design. Below, the stick figure represents users and each oval will show one of the tasks the user hopes to be able to use the database for. UML is great for mock-ups, but you should also include a detailed document that provides deeper insight into the tasks below.
Now imagine we want to create a database to store plant data:
Using this data, we can come up with a few basic use cases
Use case 1: Enter (or edit) all the data we have about each plant; that is, plant ID, genus, species, common name, and uses.
Use case 2: Find or report information about a plant (or every plant) and see what it is useful for.
Use case 3: Specify a use and find the appropriate plants (or report for all uses).
How does our existing table design handle our use cases:
1.Can we maintain data? Yes
2.Given a plant can we return the uses? Yes
3.Given a use can we return the plant? Not really
We need to re-examine this data from a class point of view
We are dealing with 2 classes in the Plant data:
1.Plant
2.Use
•One plant can have many uses
•This is an example of a relationship between classes
•Relationships between classes are represented with a line in UML
•We need more details besides just a line to know how classes relate
•The pair of numbers at each end of the line indicates how many objects of one class can be associated with a particular object of the other class
•The first number is the minimum number (0 or 1 to indicate whether there must be a related object)
•The second number is the greatest number of related objects (1 or n to represent many)
Design Phase
•You spend a lot of time in the top 2 quadrants
•It is an iterative process, not simply linear
•Keep reviewing the model to ensure it satisfies the problem
•Once you have a model that works, move on to design
•For the database world, design involves:
Converting our Class Diagram into Database Objects: Tables, Keys, and Relationships
Application Phase
•Now that you have a database foundation in place, the Application phase builds upon it by adding additional functionality for the users
•The Application phase satisfies the Use Cases:
Input Use Cases will most likely be satisfied with Forms
Output Use Cases will most likely be satisfied with Reports
Database = A collection of structured tables designed to store data
Table = A database object that stores data by organizing it into rows and columns
Field = Each column in a database table is called a field
Record = Each row in a database table is called a record
We want to create databases that will:
1.Store our data
2.Let us interact and ask questions of the data
3.Retrieve or export the data
In order to do this, we need to have a properly designed database
Example Situation #1:
A teacher puts out a sign up sheet during back to school night to allow parents to donate various classroom supplies. The parents of the class fill out the sign up sheet and it looks like this:
The next day the teacher types up the donation sheet and puts it in Excel. The teacher decides that he wants to try to build a database to keep track of what each person donated. After noticing that at most someone is donating 3 items he builds a database table that looks like this:
In Excel:
Database:
The teacher is pleased. He set out to create a database to keep track of what each parent donated. Given a parent name he can easily see their donations. However, when he wants to see all the parents that have donated tissues he ran into some problems.
Problems:
•The table answers questions in 1 direction only (given a parent you can easily return donations)
•To answer the question in the other direction (what parents donated tissues?) you need to search across 3 different fields
•The table was designed without recognizing we are dealing with 2 different classes
With a parent name provided as input (ex: Greg Carter), a record in the table can be identified. Once we have identified a record, the values for all fields in that record can be retrieved.
So, this table works to answer questions like this:
“What donations did Greg Carter provide?”
Example Situation #1 Takeaways:
1.Do not let an existing form dictate your table design (a form can be simple like a paper signup sheet or more complex like the interface of an application)
2.You must get to know your data to be able to correctly identify how many classes of data you have
3.Be careful when designing your table to answer a particular question – will you ever want to ask that question in the opposite direction?
4.Don’t rush to simply load given data into a table – take the time to think through design
Repeated Information:
•Another common problem is storing the same piece of information several times
•If you find this happening, you may be placing too much emphasis on an existing form
Example:
A business’s paper order form has customer name, address, phone number. We wouldn’t want to create a database table to keep storing all the information for every single order. It is inefficient and will most likely lead to inconsistencies and future problems.
If you see repeated information in a table, it should be a huge red flag for you to re-examine the design.
Designing for a single report:
•You can’t allow an existing form to determine your table design
•Similarly, you can’t allow a report to determine your table design
•Think about reports as nicely presented data coming out of your database
Data scientist, data architect, data engineer, database administrator, data analyst: all of these jobs have 1 big thing in common – they all work with databases. So what exactly are databases?
A database is a software platform designed to store, manage, and manipulate data. They come in different flavors from small desktop based solutions to large enterprise databases sprawling across 100’s or 1000’s of servers.
Databases are used for all types of business and personal needs. Some common examples are transactional databases > like the ones run on cash registers in a retail store. They track inventory, prices, and sales.
Data warehouses: they are used by data analysts and business intelligence teams to run reports and build dashboards against. Also, there are unstructured databases that hold information like documents, images, audio, and free text.
From a very broad view, databases can be broken down into two categories: structure and unstructured. Another way you may describe it is SQL vs NoSQL. While not all structured databases run SQL, the vast majority do, so for the sake of this article, we will use SQL and unstructured interchangeably.
Structured SQL databases are still king of the data world at the moment. Most companies use them for both day to day functions as well as reporting and advanced analytics. These databases fall under the umbrella of relational databases.
RDBMS = Relational Database Management System
RDBMS databases stores data in one or more tables formatted into rows and columns (think Excel or Google Sheets). These tables are typically set up to handle some specific data, like an HR employee list or a student grade table. The tables can be joined using SQL to create rich datasets.
In the picture above, we have 2 tables. Using the ID from the first table, you can determine who the instructors are for each of the classes in table 2. This is, at the most basic level, a relational database.
Relational databases are normalized, meaning the duplicates are removed and big tables are broken up in to small more specific tables. This is done to save disk space as well as improve performance. I promise, I will have a whole write up dedicated solely to data normalization, but for now, just know it is a property of RDMS.
Other factors of Relation database design include:
ACID – set of rules to guide database design
Atomicity – integrity of an entire database transaction
Ex: if you are updating a person’s first name, the entire value must get updated to be successful (not just the first letter); no view of partial transactions in progress
Consistency – only data that pass validation rules are permitted
Ex: email address requires an @ otherwise it should not be written to the database
Isolation – the ability for a database to process multiple transactions simultaneously
Ex: if you are performing 2 updates, the first must complete before the second
Durability – once data is saved it should remain saved even when the machine shuts down
Ex: if a machine shuts down in the middle of an update, it should be rolled back; if an update is completed and a machine shuts down then the update should exist on the restart
Non-relational databases (NoSQL) are designed to fill in the gaps left by RDMS. These databases scale easily. Their loose approach to storing and managing data allow them to scale across multiple servers, allowing them to grow with demand and shrink as demand shrinks. They have a more flexible design, allowing for storage of data not easily handled by a RDMS such as: images, audio, documents.
When it comes to growth and scaling, there is a clear difference between the two approaches
The following articles will be based on RDMS, mostly due to the fact they are still the primary database in use today, and also they are easier to conceptualize. Don’t worry though, everything you learn here will help you to later understand the world of NoSQL unstructured data.